Bài 22: Rừng ngẫu nhiên (Random Forests)
Khi mối quan hệ giữa một tập hợp các biến dự báo và một biến phản hồi rất phức tạp, chúng ta thường sử dụng các phương pháp phi tuyến tính để mô hình hóa mối quan hệ giữa chúng.
Một trong những phương pháp đó là cây phân lớp và hồi quy (thường được viết tắt là CART), sử dụng một tập hợp các biến dự báo để xây dựng cây quyết định dự đoán giá trị của một biến phản hồi.

Lợi ích của cây quyết định là chúng dễ diễn giải và hình dung. Khi chiều cao của cây tăng lên tì mô hình có xu hướng bị chênh lệch cao. Nếu chúng ta chia tập dữ liệu thành hai nửa và áp dụng cây quyết định cho cả hai nửa, kết quả có thể hoàn toàn khác nhau.
Một cách để giảm phương sai của cây quyết định là sử dụng một phương pháp được gọi là đóng gói, hoạt động như sau:
1. Lấy b mẫu khởi động từ tập dữ liệu ban đầu.
2. Xây dựng cây quyết định cho mỗi mẫu khởi động.
3. Tính trung bình các dự đoán của từng cây để đưa ra mô hình cuối cùng.
Lợi ích của cách tiếp cận này là mô hình đóng gói thường cung cấp sự cải thiện về tỷ lệ lỗi thử nghiệm so với một cây quyết định duy nhất.
Nhược điểm là các dự đoán từ tập hợp các cây đóng gói có thể tương quan cao nếu có một yếu tố dự đoán rất mạnh trong tập dữ liệu. Trong trường hợp này, hầu hết hoặc tất cả các cây có túi sẽ sử dụng dự đoán này cho lần phân chia đầu tiên, điều này sẽ tạo ra các cây tương tự nhau và có các dự đoán tương quan cao.
Do đó, khi chúng ta tính trung bình các dự đoán của mỗi cây để đưa ra mô hình đóng gói cuối cùng, có thể mô hình này không thực sự làm giảm phương sai nhiều so với một cây quyết định duy nhất.
Một cách để giải quyết vấn đề này là sử dụng một phương pháp được gọi là rừng ngẫu nhiên (random forest).
Rừng ngẫu nhiên là gì?
Tuy nhiên, khi xây dựng cây quyết định cho mỗi mẫu khởi động, mỗi lần phân chia trong cây được xem xét, chỉ một mẫu ngẫu nhiên gồm m yếu tố dự đoán được coi là ứng viên tách từ tập hợp đầy đủ p yếu tố dự đoán p.
Dưới đây là cách mà phương pháp tạo rừng ngẫu nhiên sử dụng để xây dựng mô hình:
1. Lấy b mẫu khởi động từ tập dữ liệu ban đầu.
2. Xây dựng cây quyết định cho mỗi mẫu khởi động.
- Khi xây dựng cây, mỗi lần phân tách được xem xét, chỉ một mẫu ngẫu nhiên gồm m yếu tố dự đoán được coi là ứng viên tách từ tập hợp đầy đủ p yếu tố dự đoán.
3. Tính trung bình các dự đoán của từng cây để đưa ra mô hình cuối cùng.
Khi sử dụng phương pháp này, việc sưu tập các cây trong một rừng ngẫu nhiên có liên quan đến việc so sánh những cây được tạo ra bằng cách đóng gói.
Do đó, khi chúng ta lấy các dự đoán trung bình của mỗi cây để đưa ra mô hình cuối cùng, nó có xu hướng ít biến động hơn và dẫn đến tỷ lệ lỗi thử nghiệm thấp hơn so với mô hình đóng gói.
Khi sử dụng rừng ngẫu nhiên, chúng ta thường coi các yếu tố dự đoán m = √p là các ứng cử viên phân tách mỗi khi chúng ta tách một cây quyết định.
Ví dụ: nếu chúng ta có p = 16 tổng số dự đoán trong một tập dữ liệu thì chúng ta thường chỉ coi m = √16 = 4 dự đoán là ứng viên phân tách tiềm năng tại mỗi lần phân tách.
Lưu ý:
Lưu ý rằng nếu chúng ta chọn m = p (tức là chúng ta coi tất cả các yếu tố dự đoán là các ứng viên được phân chia tại mỗi lần phân tách) thì điều này tương đương với việc sử dụng phương pháp đóng gói.
Ước tính lỗi ngoài gói
Tương tự như đóng gói, chúng ta có thể tính toán sai số thử nghiệm của một mô hình rừng ngẫu nhiên bằng cách sử dụng ước lượng ngoài gói.
Có thể chỉ ra rằng mỗi mẫu khởi động chứa khoảng 2/3 số quan sát từ tập dữ liệu ban đầu. 1/3 còn lại của các quan sát không được sử dụng để đưa vào cây được gọi là quan sát ngoài túi (OOB) .
Chúng ta có thể dự đoán giá trị cho quan sát thứ i trong tập dữ liệu ban đầu bằng cách lấy dự đoán trung bình từ mỗi cây trong đó quan sát đó là OOB.
Chúng ta có thể sử dụng cách tiếp cận này để đưa ra dự đoán cho tất cả n quan sát trong tập dữ liệu gốc và do đó tính toán tỷ lệ lỗi, là ước tính hợp lệ của sai số thử nghiệm.
Lợi ích của việc sử dụng phương pháp này để ước tính lỗi kiểm tra là nhanh hơn nhiều so với xác thực chéo k-lần , đặc biệt là khi tập dữ liệu lớn.
Ưu và nhược điểm của Rừng ngẫu nhiên
Rừng ngẫu nhiên mang lại những lợi ích sau :
- Trong hầu hết các trường hợp, rừng ngẫu nhiên sẽ cải thiện độ chính xác so với mô hình đóng gói và đặc biệt là so với cây quyết định đơn lẻ.
- Không cần xử lý trước để sử dụng rừng ngẫu nhiên.
Tuy nhiên, rừng ngẫu nhiên có những nhược điểm tiềm ẩn sau :
- Khó giải thích.
- Chi phí tính toán lớn, khi làm việc trên các tập dữ liệu lớn.
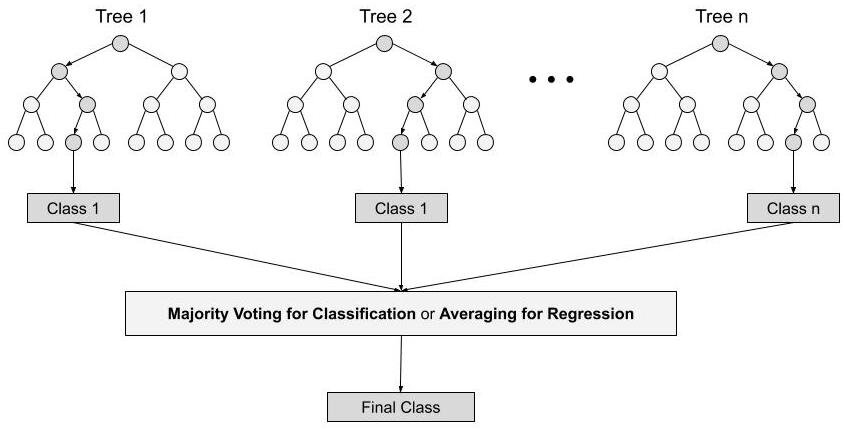
Các bước cơ bản của thuật toán rừng ngẫu nhiên:
Bước 1 : Trong Rừng ngẫu nhiên, n số mẫu tin ngẫu nhiên được lấy từ tập dữ liệu có k số mẫu tin.
Bước 2 : Các cây quyết định riêng lẻ được xây dựng cho từng mẫu.
Bước 3 : Mỗi cây quyết định sẽ tạo ra một đầu ra.
Bước 4 : Kết quả cuối cùng được xem xét dựa trên Biểu quyết đa số hoặc Trung bình (Majority Voting or Averaging) cho Phân lớp và hồi quy tương ứng.
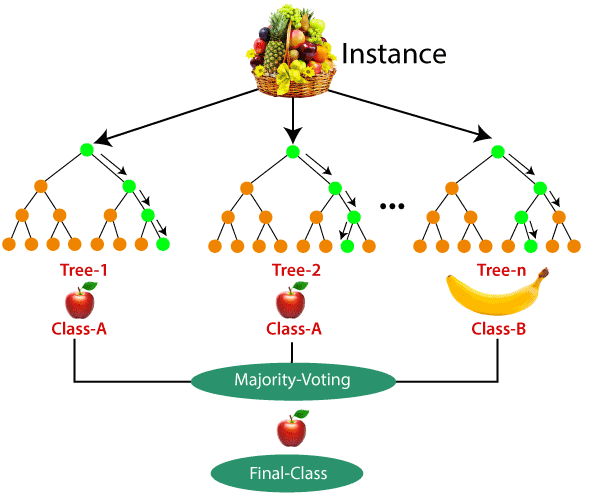
Ví dụ: coi giỏ trái cây là dữ liệu như trong hình dưới đây. Bây giờ số lượng n mẫu được lấy từ giỏ trái cây và một cây quyết định riêng lẻ được xây dựng cho mỗi mẫu. Mỗi cây quyết định sẽ tạo ra một đầu ra như trong hình. Kết quả cuối cùng được xem xét dựa trên biểu quyết đa số. Trong hình dưới đây, bạn có thể thấy rằng cây quyết định phần lớn cho đầu ra là một quả táo khi so sánh với một quả chuối, vì vậy sản phẩm cuối cùng được coi là một quả táo.
Các tính năng quan trọng của rừng ngẫu nhiên
1. Tính đa dạng- Không phải tất cả các thuộc tính / biến / tính năng đều được xem xét trong khi tạo một cây riêng lẻ, mỗi cây là khác nhau.
2. Tránh được các sai lệch khi số chiều của không gian mẫu lớn- Vì mỗi cây không xem xét tất cả các đặc điểm nên không gian đặc trưng được giảm đi.
3. Song song hóa - Mỗi cây được tạo độc lập từ các dữ liệu và thuộc tính khác nhau. Điều này có nghĩa là chúng ta có thể tận dụng CPU để xây dựng các rừng ngẫu nhiên.
4. Phân tách Train-Test- Trong một rừng ngẫu nhiên, chúng ta không cần phải tách biệt dữ liệu để huấn luyện và dữ liệu kiểm tra, vì sẽ luôn có 30% dữ liệu không được cây quyết định nhìn thấy.
5. Tính ổn định - Tính ổn định phát sinh do kết quả dựa trên biểu quyết đa số / tính trung bình.
Sự khác biệt giữa cây quyết định và rừng ngẫu nhiên
Rừng ngẫu nhiên là tập hợp các cây quyết định; tuy nhiên, có rất nhiều khác biệt giữa chúng.
Cây quyết định | Rừng ngẫu nhiên |
| 1. Cây quyết định thường gặp phải vấn đề overfits, nếu nó được phép phát triển mà không có bất kỳ sự kiểm soát nào. | 1. Rừng ngẫu nhiên được tạo ra từ các tập hợp con dữ liệu và đầu ra cuối cùng dựa trên xếp hạng trung bình hoặc đa số và do đó vấn đề overfits luôn được quan tâm trước để ngăn chặn. |
| 2. Cây quyết định sẽ nhanh hơn trong tính toán. | 2. Nó tương đối chậm hơn. |
| 3. Khi một tập dữ liệu với các tính năng được lấy làm đầu vào bởi cây quyết định, nó sẽ hình thành một số bộ quy tắc để thực hiện dự đoán. | 3. Rừng ngẫu nhiên chọn ngẫu nhiên các quan sát, xây dựng cây quyết định và lấy kết quả trung bình. Nó không sử dụng bất kỳ bộ công thức nào. |
Các Hyperparameter quan trọng
Hyperparameter được sử dụng trong các rừng ngẫu nhiên để nâng cao hiệu suất và khả năng dự đoán của các mô hình hoặc để làm cho mô hình nhanh hơn.
Các Hyperparameter sau làm tăng khả năng dự đoán:
1. n_estimators - số lượng cây mà thuật toán xây dựng trước khi tính trung bình các dự đoán.
2. max_features - số lượng tối đa các đối tượng rừng ngẫu nhiên xem xét việc tách một nút.
3. mini_sample_leaf - xác định số lá tối thiểu cần thiết để tách một nút bên trong.
Các Hyperparameter sau làm tăng tốc độ:
1. n_jobs - nó cho biết có bao nhiêu bộ vi xử lý được phép sử dụng. Nếu giá trị là 1, nó chỉ có thể sử dụng một bộ xử lý nhưng nếu giá trị là -1 thì không có giới hạn.
2. random_state - kiểm soát tính ngẫu nhiên của mẫu. Mô hình sẽ luôn tạo ra các kết quả giống nhau nếu nó có một giá trị xác định của trạng thái ngẫu nhiên và nếu nó được cung cấp cùng một siêu tham số và cùng một dữ liệu huấn luyện.
3. oob_score - OOB có nghĩa là ra khỏi gói. Đây là phương pháp xác nhận chéo rừng ngẫu nhiên. Trong phần này, một phần ba mẫu không được sử dụng để huấn luyện dữ liệu thay vào đó được sử dụng để đánh giá hiệu suất của nó. Các mẫu này được gọi là mẫu ngoài túi.
Ví dụ về rừng ngẫu nhiên với Python
1. Import các thư viện
# Importing the required libraries import pandas as pd, numpy as np import matplotlib.pyplot as plt, seaborn as sns %matplotlib inline
2. import các dataset dữ liệu.
# Reading the csv file and putting it into 'df' object
df = pd.read_csv('heart_v2.csv')
df.head()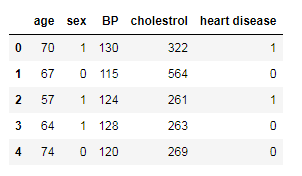
3. Gán các biến X và biến mục tiêu y.
# Putting feature variable to X
X = df.drop('heart disease',axis=1)
# Putting response variable to y
y = df['heart disease']4. Phân tách tập huấn luyện và tập test (Train-Test-Split is performed)
# now lets split the data into train and test from sklearn.model_selection import train_test_split
# Splitting the data into train and test X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) X_train.shape, X_test.shape
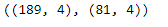
3. Import các thư viện quan trọng cho rừng ngẫu nhiên và fit dữ liệu.
from sklearn.ensemble import RandomForestClassifier
classifier_rf = RandomForestClassifier(random_state=42, n_jobs=-1, max_depth=5,
n_estimators=100, oob_score=True)%%time classifier_rf.fit(X_train, y_train)

# checking the oob score classifier_rf.oob_score_
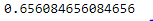
4. Đưa ra các hyperparameter để điều chỉnh cho mô hình Random Forest ở đây sử dụng GridSearchCV, và fit dữ liệu.
rf = RandomForestClassifier(random_state=42, n_jobs=-1)
params = {
'max_depth': [2,3,5,10,20],
'min_samples_leaf': [5,10,20,50,100,200],
'n_estimators': [10,25,30,50,100,200]
}from sklearn.model_selection import GridSearchCV
# Instantiate the grid search model
grid_search = GridSearchCV(estimator=rf,
param_grid=params,
cv = 4,
n_jobs=-1, verbose=1, scoring="accuracy")%%time
grid_search.fit(X_train, y_train)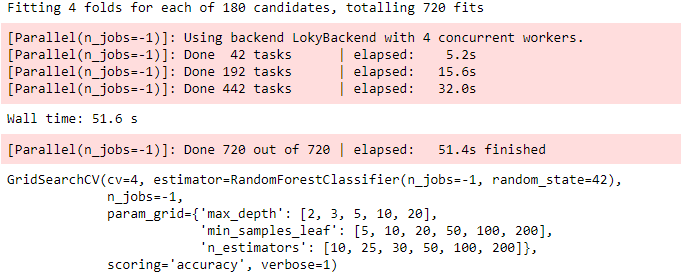
grid_search.best_score_
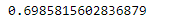
rf_best = grid_search.best_estimator_ rf_best
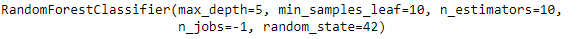
Từ việc điều chỉnh hyperparameter, chúng ta có thể tìm ra các công cụ ước tính tốt nhất như sẽ được hiển thị. Bộ tham số tốt nhất được xác định là: max_depth=5, min_samples_leaf=10,n_estimators=10
5. Minh hoạ bằng hình ảnh
from sklearn.tree import plot_tree plt.figure(figsize=(80,40)) plot_tree(rf_best.estimators_[5], feature_names = X.columns,class_names=['Disease', "No Disease"],filled=True);
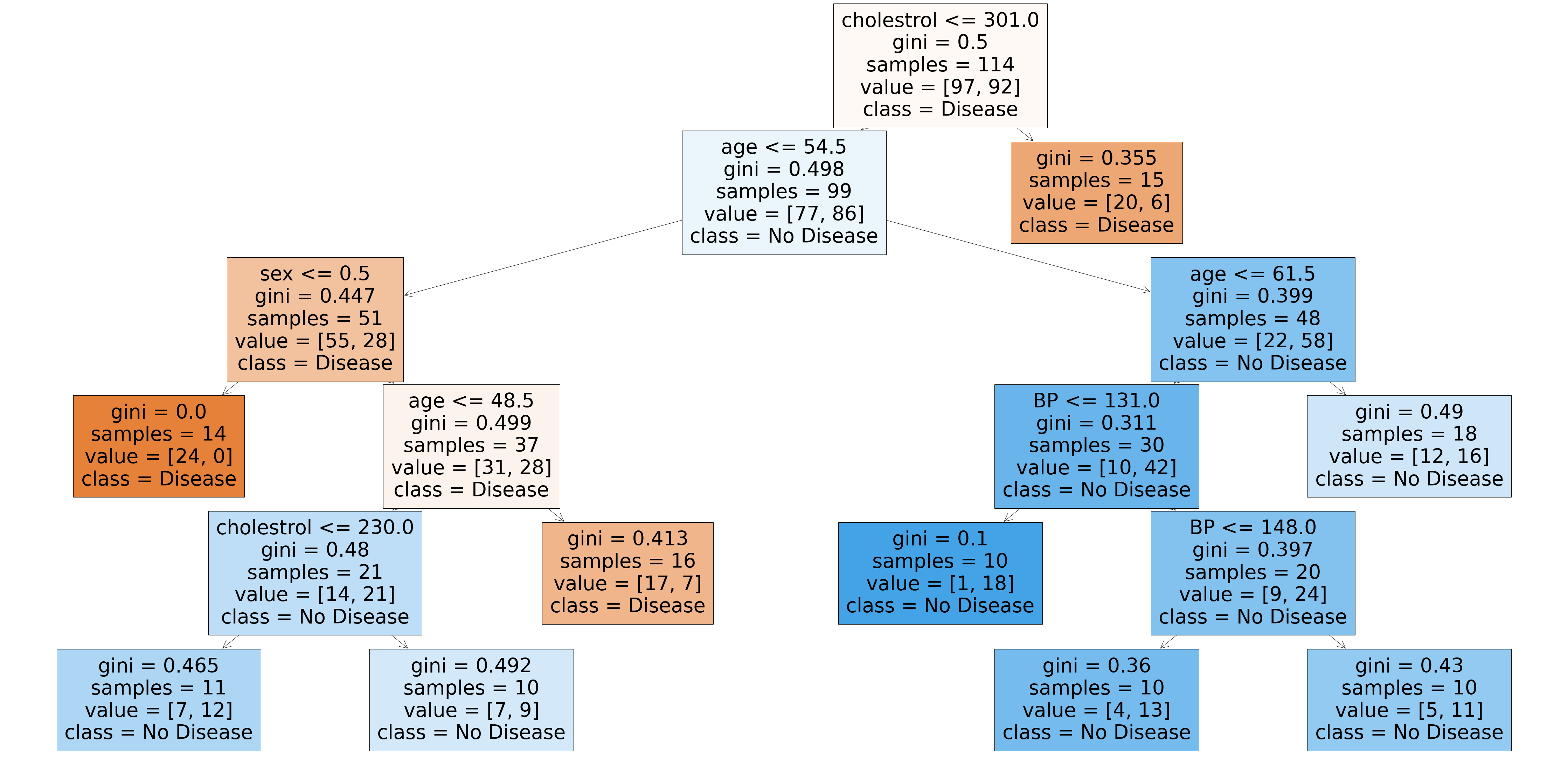
from sklearn.tree import plot_tree plt.figure(figsize=(80,40)) plot_tree(rf_best.estimators_[7], feature_names = X.columns,class_names=['Disease', "No Disease"],filled=True);
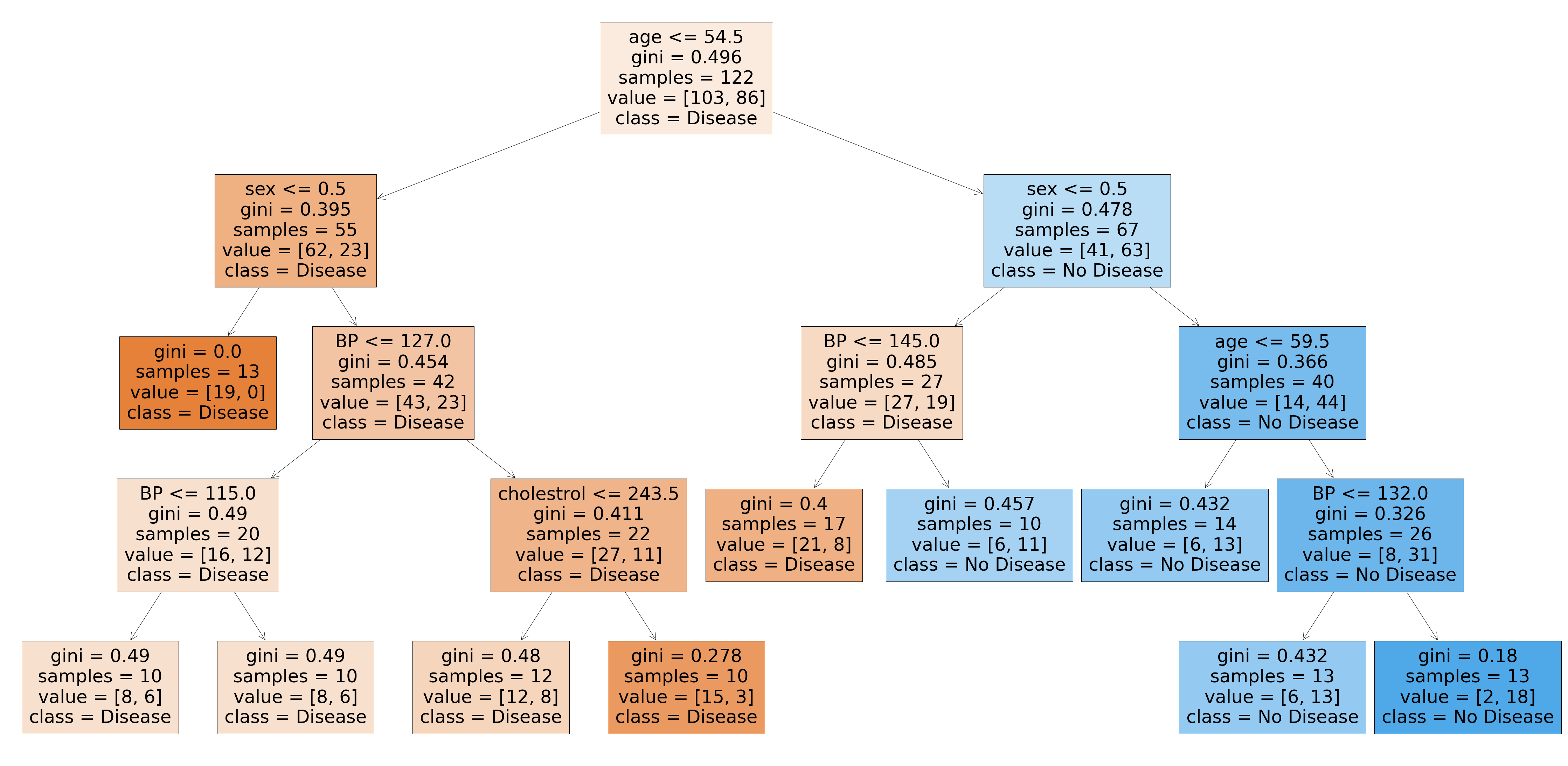
Các cây được tạo bởi ước tính_ [5] và ước tính_ [7] là khác nhau. Vì vậy, chúng ta có thể nói rằng mỗi cây là độc lập với cây kia.
6. Sắp xếp dữ liệu với sự hõ trợ của những tính năng quan trọng
rf_best.feature_importances_

imp_df = pd.DataFrame({
"Varname": X_train.columns,
"Imp": rf_best.feature_importances_
})imp_df.sort_values(by="Imp", ascending=False)
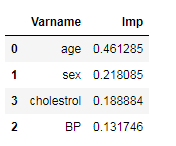
Ưu điểm và nhược điểm của thuật toán rừng ngẫu nhiên
Thuận lợi
1. Có thể được sử dụng trong các bài toán phân lớp và hồi quy.
2. Giải quyết vấn đề overfits vì đầu ra dựa trên biểu quyết đa số hoặc lấy trung bình.
3. Hoạt động tốt ngay cả khi dữ liệu chứa giá trị null / thiếu.
4. Mỗi cây quyết định được tạo là độc lập với cây khác, do đó có thể song song hóa thuật toán trong triển khai thực hiện.
5. Có tính ổn định cao khi các câu trả lời trung bình được đưa ra bởi một số lượng lớn các cây được lấy.
6. Nó duy trì sự đa dạng vì tất cả các thuộc tính không được xem xét trong khi tạo mỗi cây quyết định mặc dù nó không đúng trong mọi trường hợp.
7. Nó miễn nhiễm với lời nguyền về chiều không gian. Vì mỗi cây không xem xét tất cả các thuộc tính nên không gian đối tượng bị giảm.
8. Chúng ta không cần phải tách biệt dữ liệu thành huấn luyện và kiểm tra vì sẽ luôn có 30% dữ liệu không được nhìn thấy bởi cây quyết định được tạo ra từ bootstrap.
Nhược điểm
1. Rừng ngẫu nhiên rất phức tạp khi so sánh với các cây quyết định nơi mà các quyết định có thể được thực hiện bằng cách đi theo con đường của cây.
2. Thời gian đào tạo nhiều hơn so với các mô hình khác do tính phức tạp của nó. Bất cứ khi nào nó phải đưa ra dự đoán, mỗi cây quyết định phải tạo ra đầu ra cho dữ liệu đầu vào đã cho.
Nhận xét
Đăng nhận xét