Bài 21: Giới thiệu về đóng gói (bagging) trong Máy học
Khi mối quan hệ giữa một tập hợp các biến dự báo và một biến phản hồi là tuyến tính, chúng ta có thể sử dụng các phương pháp như hồi quy tuyến tính bội, để mô hình hóa mối quan hệ giữa các biến.
Tuy nhiên, khi mối quan hệ phức tạp hơn thì chúng ta thường phải dựa vào các phương pháp phi tuyến tính.
Một trong những phương pháp như vậy là cây phân loại và hồi quy (thường được viết tắt là CART), sử dụng một tập hợp các biến dự báo để xây dựng cây quyết định dự đoán giá trị của một biến phản hồi.

Tuy nhiên, nhược điểm của các mô hình CART là chúng có xu hướng chịu phương sai cao. Đó là, nếu chúng ta chia tập dữ liệu thành hai nửa và áp dụng cây quyết định cho cả hai nửa, kết quả có thể hoàn toàn khác nhau.
Một phương pháp mà chúng ta có thể sử dụng để giảm phương sai của các mô hình CART được gọi là đóng gói (bagging), đôi khi được gọi là tích hợp bootstrap (bootstrap aggregating).
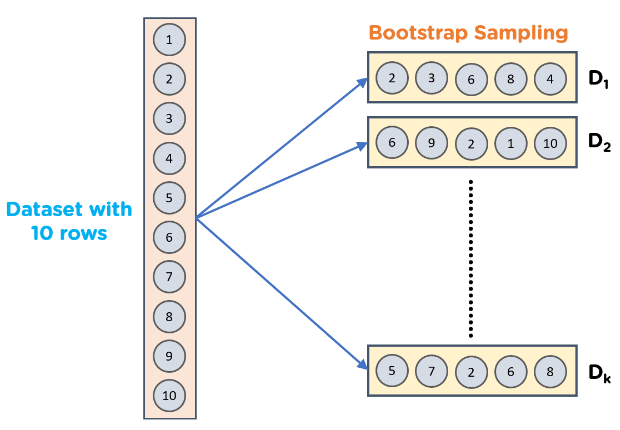
Đóng gói là gì?
Khi chúng ta tạo một cây quyết định, chúng ta chỉ sử dụng một tập dữ liệu huấn luyện để xây dựng mô hình.
Tuy nhiên, đóng gói sử dụng phương pháp sau:
1. Lấy b mẫu khởi động (bootstrapped samples) từ tập dữ liệu ban đầu.
- Nhớ lại rằng một mẫu khởi động là một mẫu của tập dữ liệu ban đầu, trong đó các quan sát được thực hiện thay thế.
2. Xây dựng cây quyết định cho mỗi mẫu khởi động.
3. Tính trung bình các dự đoán của từng cây để đưa ra mô hình cuối cùng.
- Đối với cây hồi quy, chúng ta lấy giá trị trung bình của dự đoán được thực hiện bởi các B - cây.
- Đối với cây phân lớp, chúng ta lấy dự đoán phổ biến nhất được thực hiện bởi các B - cây.
Phương pháp bagging có thể được sử dụng với bất kỳ thuật toán học máy nào, nhưng nó đặc biệt hữu ích cho cây quyết định vì chúng vốn có phương sai cao và việc đóng gói có thể giảm đáng kể phương sai, dẫn đến sai số thử nghiệm thấp hơn.
Để áp dụng đóng bao cho cây quyết định, chúng ta phát triển từng B -cây riêng lẻ mà không cần cắt tỉa. Điều này dẫn đến các cây riêng lẻ có phương sai cao, nhưng sai lệch thấp. Sau đó, khi chúng ta lấy các dự đoán trung bình từ những cây này, chúng ta có thể giảm phương sai.
Trong thực tế, hiệu suất tối ưu thường xảy ra với 50 đến 500 cây, nhưng có thể phù hợp với hàng nghìn cây để tạo ra mô hình cuối cùng.
Chỉ cần lưu ý rằng việc xây dựng nhiều cây sẽ đòi hỏi chi phí tính toán cao, điều này có thể là một vấn đề tùy thuộc vào kích thước của tập dữ liệu.
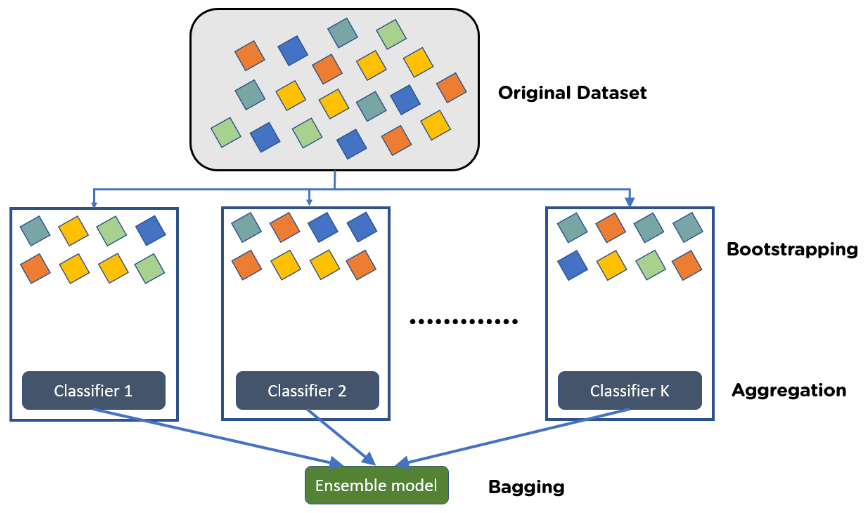
Ước tính lỗi ngoài gói
Ước tính này chỉ ra rằng, chúng ta có thể tính toán sai số thử nghiệm của một mô hình đóng gói mà không cần dựa vào xác nhận chéo k-lần .
Lý do là vì có thể chỉ ra rằng mỗi mẫu khởi động chứa khoảng 2/3 số quan sát từ tập dữ liệu ban đầu. 1/3 còn lại của các quan sát không được sử dụng để đưa vào cây đóng góiđược gọi là quan sát ngoài bao (out-of-bag - OOB) .
Chúng ta có thể dự đoán giá trị cho quan sát thứ i trong tập dữ liệu ban đầu bằng cách lấy dự đoán trung bình từ mỗi cây trong đó quan sát đó là OOB.
Chúng ta có thể sử dụng cách tiếp cận này để đưa ra dự đoán cho tất cả n quan sát trong tập dữ liệu gốc và do đó tính toán tỷ lệ lỗi, là ước tính hợp lệ của sai số thử nghiệm.
Lợi ích của việc sử dụng phương pháp này để ước tính lỗi kiểm tra là nhanh hơn nhiều so với xác thực chéo k-lần, đặc biệt là khi tập dữ liệu lớn.
Tầm quan trọng của các dự báo
Hãy nhớ lại rằng một trong những lợi ích của cây quyết định là chúng dễ diễn giải và hình ảnh hoá.
Thay vào đó, khi chúng ta sử dụng đóng gói, chúng ta không còn có thể giải thích hoặc hình dung một cây riêng lẻ vì mô hình đóng gói cuối cùng là kết quả của việc lấy trung bình nhiều cây khác nhau. Chúng ta đạt được độ chính xác của dự đoán với chi phí tính toán vừa phải.
Tuy nhiên, chúng ta vẫn có thể thấy được tầm quan trọng của từng biến dự báo bằng cách tính toán tổng mức giảm RSS (tổng bình phương còn lại) do sự phân tách đối với một biến dự báo nhất định, được tính trung bình trên tất cả các B - cây. Giá trị càng lớn thì yếu tố dự đoán càng quan trọng.

Vì vậy, mặc dù chúng ta không thể diễn giải chính xác mô hình đóng gói cuối cùng, chúng tôi vẫn có thể biết được tầm quan trọng của mỗi biến dự báo khi dự đoán phản hồi.
Vượt ra ngoài đóng gói (Going Beyond Bagging)
Lợi ích của việc đóng gói là phương pháp này thường cung cấp sự cải thiện về tỷ lệ lỗi thử nghiệm so với một cây quyết định duy nhất.
Nhược điểm là các dự đoán từ tập hợp các cây có gói có thể tương quan cao nếu có một yếu tố dự đoán có ảnh hưởng lớn trong tập dữ liệu.
Trong trường hợp này, hầu hết hoặc tất cả các cây có gói sẽ sử dụng dự đoán này cho lần phân chia đầu tiên, điều này sẽ tạo ra các cây tương tự nhau và có các dự đoán tương quan cao.
Một cách để giải quyết vấn đề này là thay vào đó sử dụng các rừng ngẫu nhiên (random forest), sử dụng một phương pháp tương tự như đóng bao nhưng có thể tạo ra các cây có liên quan, điều này thường dẫn đến tỷ lệ lỗi thử nghiệm thấp hơn.
Các bước thực hiện đóng bao [https://www.simplilearn.com/tutorials/machine-learning-tutorial/bagging-in-machine-learning]
- Xem xét rằng tập huấn luyện có n quan sát và m đặc trưng. Các mẫu liên tiếp nhau nên được chọn từ tập dữ liệu huấn luyện mà không cần thay thế
- Một tập hợp con gồm m đối tượng được chọn ngẫu nhiên và một mô hình được tạo ra bằng cách sử dụng các quan sát mẫu
- Sử dụng các dữ liệu có khả năng cung cấp sự phân tách tốt nhất để phân tách các nút
- Cây đang phát triển nên là cây có gốc tốt nhất.
- Lặp lại các bước trên n lần. Tổng hợp kết quả của từng cây quyết định để đưa ra dự đoán tốt nhất
- Xem xét rằng tập huấn luyện có n quan sát và m đặc trưng. Các mẫu liên tiếp nhau nên được chọn từ tập dữ liệu huấn luyện mà không cần thay thế
- Một tập hợp con gồm m đối tượng được chọn ngẫu nhiên và một mô hình được tạo ra bằng cách sử dụng các quan sát mẫu
- Sử dụng các dữ liệu có khả năng cung cấp sự phân tách tốt nhất để phân tách các nút
- Cây đang phát triển nên là cây có gốc tốt nhất.
- Lặp lại các bước trên n lần. Tổng hợp kết quả của từng cây quyết định để đưa ra dự đoán tốt nhất
Lợi ích của việc đóng gói trong học máy
- Đóng gói giảm thiểu overrfits dữ liệu
- Cải thiện độ chính xác của mô hình
- Xử lý hiệu quả số chiều của dữ liệu
- Đóng gói giảm thiểu overrfits dữ liệu
- Cải thiện độ chính xác của mô hình
- Xử lý hiệu quả số chiều của dữ liệu
Bagging với Python sử dụng tập dữ liệu IRIS
Import các thư viện

Tải dữ liệu
Chia dataset thành tập huấn luyện và tập thử nghiệm (testing)

Tạo tập con dữ liệu để huấn luyện mô hình

Định nghĩa cây quyết định

Mô hình phân lớp đóng gói (Bagging classification model)

Huấn luyện mô hình và cho ra độ chính xác của nó
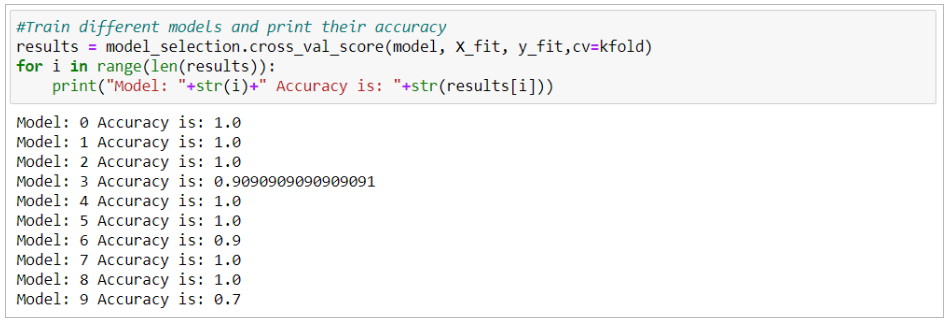
Cho ra độ chính xác

Cho ra độ chính xác của mô hình

Đóng gói là một khái niệm quan trọng trong thống kê và học máy giúp tránh trang bị quá nhiều dữ liệu. Đây là một thủ tục lấy trung bình mô hình thường được sử dụng trong cây quyết định, nhưng nó cũng có thể được áp dụng cho các thuật toán khác.
Nhận xét
Đăng nhận xét